LM Studio 0.3.14: マルチGPUコントロール 🎛️

LM Studio 0.3.14には、2つ以上のGPUを備えたセットアップ向けの新しいコントロールが搭載されました
LM Studio 0.3.14では、マルチGPUセットアップ向けに新たな詳細なコントロールが導入されました。新機能には、特定のGPUの有効化/無効化、割り当て戦略(均等、優先順位)の選択、モデルの重みを専用GPUメモリに限定する機能などが含まれます。
アプリ内更新またはhttps://lmstudio.dokyumento.jp/downloadからアップグレードしてください。
GPUブルジョワジー 🎩
システムに2つ以上のGPUがある場合、もはや「GPU貧乏」とは見なされないかもしれません。しかし、大きな力には大きな責任が伴います。最高のパフォーマンスを引き出すためには、GPUを賢く管理する必要があります。
LM Studio 0.3.14では、GPUリソースをより良く、より意図的に管理するための新しい調整機能が導入されました。これらの新機能の一部はNVIDIA GPUでのみ利用可能です。AMD GPU向けにも提供できるよう積極的に取り組んでいます。
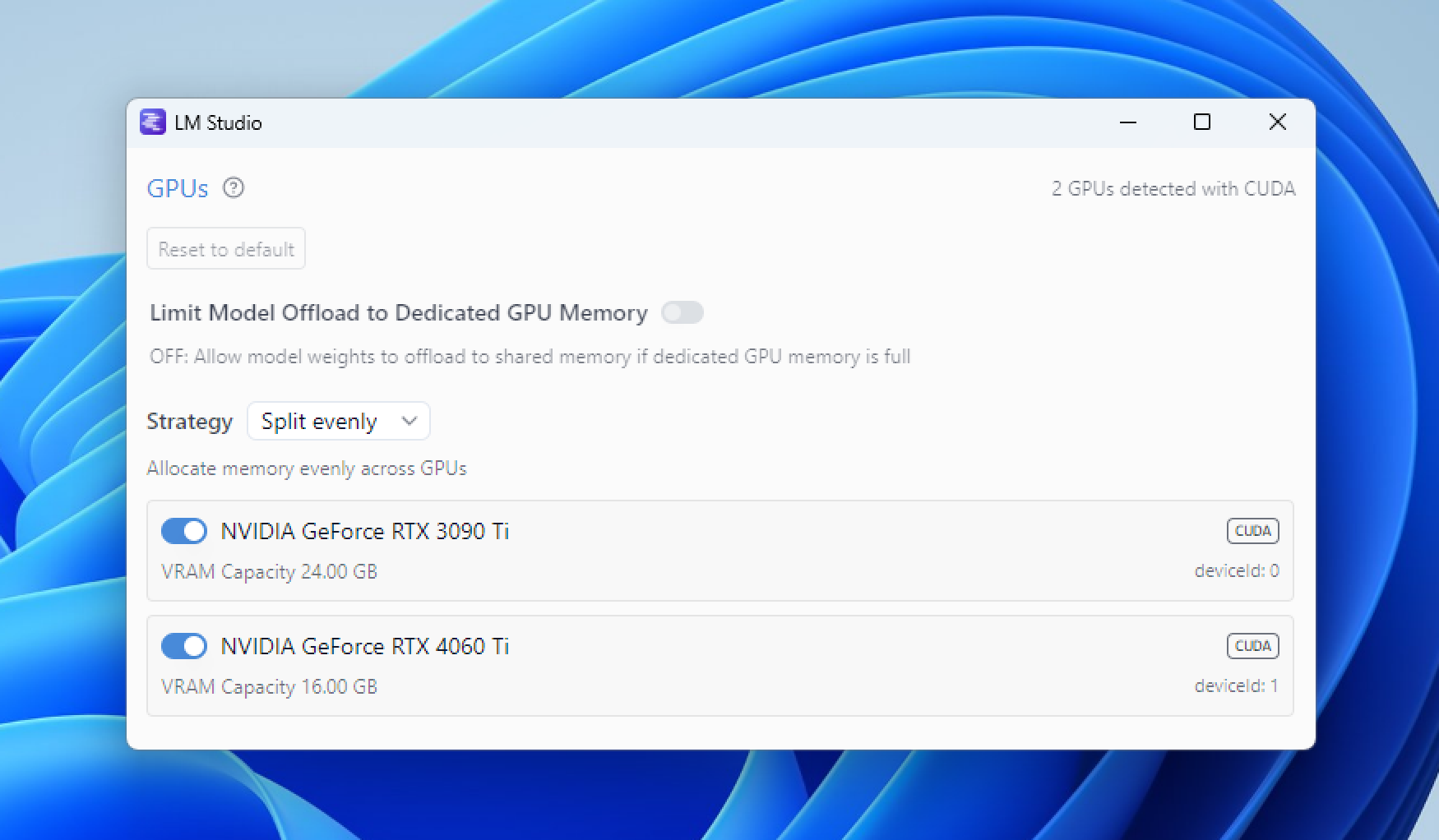
マルチGPUコントロール
Ctrl+Shift+Alt+Hを使用して、それらを新しいウィンドウでポップアップ表示します。
GPUコントロールを開くには、WindowsまたはLinuxではCtrl+Shift+H、MacではCmd+Shift+Hを押します。ポップアウトウィンドウでGPUコントロールを開くには、Ctrl+Alt+Shift+H/Cmd+Option+Shift+Hを押します。
最適な構成についてさらに学ぶにつれて、手動コントロールに加えて自動モードを追加することを目指します。これらの機能はLM StudioのGUIを介して利用可能であり、将来的にはlms CLIを介しても利用できるようになります。
特定のGPUを有効または無効にする
各GPUの隣にあるスイッチを使用して、有効または無効にします。GPUを無効にすると、LM StudioはそのGPUを使用しません。これは、強力なGPUとそうでないGPUが混在している場合や、他のタスクのためにGPUを確保したい場合に役立ちます。
ビデオでは、GPU 1を無効にしてからモデルをロードする様子が示されています。モデルはGPU 0にのみロードされ、GPU 1では何も動作していません。
GPU 1を無効にし、GPU 0にのみモデルをロードする
モデルオフロードを専用GPUメモリに限定する
現在CUDAのみ対応
LLMはメモリを大量に消費する可能性があります。一般的に最も多くのメモリを占有するのは、モデルの重みと会話コンテキストバッファです。モデルの重みが単一のGPUの専用メモリに収まりきらない場合、オペレーティングシステムが共有GPUメモリにメモリを割り当てる可能性があります。これにより、処理速度がかなり低下する可能性があります。
ビデオではまずこのオプションがOFFになっており、専用メモリと共有メモリの両方に割り当てられる様子が示されています。その後、オプションをONにすると、モデルは専用メモリにのみロードされます。
モデルオフロードを専用GPUメモリに限定する
専用GPUメモリ内のモデルの重み
「モデルオフロードを専用GPUメモリに限定する」モードは、モデルの重みが専用GPUメモリにのみロードされるようにします。モデルの重みが専用GPUメモリに収まりきらない場合、LM Studioは自動的にGPUオフロードサイズを縮小し、モデルの重みを専用GPUメモリに収め、残りをシステムRAMに配置します。
私たちのテストでは、モデルの重みを**専用GPUメモリ**と**システムRAM**に分割する方が、**共有GPUメモリ**を使用するよりも高速です。もし異なる経験をされた場合は、ぜひお知らせください!
コンテキストは共有GPUメモリに割り当てられる可能性があります
コンテキストバッファは引き続き共有メモリを使用する場合があります。モデルの重みが専用GPUメモリにいくらか余裕を持って収まる場合を考えます。コンテキストが残りの専用メモリを超えて成長するまで、モデルはフルスピードで動作します。コンテキストが共有メモリにあふれ出すにつれて、パフォーマンスは徐々に低下します。このアプローチにより、すべてのコンテキストを遅いRAMに限定するのではなく、高速な初期パフォーマンスが可能になります。
優先順位モード
現在CUDAのみ対応
GPUの優先順位を設定できるようになりました。これは具体的に何を意味するかというと
- 複数のGPUがある場合、LM StudioがモデルをGPUに割り当てようとする順序を設定できます。
- システムは、最初にリストされているGPUに多く割り当てようとします。最初のGPUがいっぱいになると、リストの次のGPUに移動し、同様に続きます。
ビデオでは、複数のモデルをロードする様子が示されています。LM StudioがGPU 1に割り当てる前に、まずGPU 0を完全に埋めることに注目してください。
順序優先モード:指定したGPU優先順位に従ってモデルを割り当てる
3つ以上のGPUセットアップをお持ちですか?ぜひご連絡ください!
私たちは、新しい機能がそのようなセットアップでどのように機能するかをテストし、フィードバックを提供してくれるユーザーを探しています。3つ以上のGPUを持つセットアップ(WindowsまたはLinux)をお持ちでしたら、[email protected]までご連絡ください。ありがとうございます!
0.3.14 - 全リリースノート
**Build 1** - New: GPU Controls 🎛️ - On multi-GPU setups, customize how models are offloaded onto your GPUs - Enable/disable individual GPUs - CUDA-specific features: - "Priority order" mode: The system will try to allocate more on GPUs listed first - "Limit Model Offload to Dedicated GPU memory" mode: The system will limit offload of model weights to dedicated GPU memory and RAM only. Context may still use shared memory - How to open GPU controls: - Windows: `Ctrl+Shift+H` - Mac: `Cmd+Shift+H` - How to open GPU controls in a pop-out window: - Windows: `Ctrl+Alt+Shift+H` - Mac: `Cmd+Option+Shift+H` - Benefit: Manage GPU settings while models are loading - LG AI EXAONE Deep reasoning model support - Improved model loader UI in small window sizes - Improve Llama model family tool call reliability through LM Studio SDK and OpenAI compatible streaming API - [SDK] Added support for GBNF grammar when using structured generation - [SDK/RESTful API] Added support for specifying presets - Fixed a bug where sometimes the last couple fragments of a prediction are lost **Build 2** - Optimized "Limit Model Offload to Dedicated GPU memory" mode in long context situations on single GPU setups - Speculative decoding draft model now respects GPU controls - [CUDA] Fixed a bug where model would crash with message "Invalid device index" - [Windows ARM] Fixed chat with document sometimes not working **Build 3** - [Advanced GPU controls] Fixed a bug where intermediate buffers were being allocated on disabled GPUs - Fixed "OpenSquareBracket !== CloseStatement" bug with Nemotron model - Fixed a bug where Nemotron GGUF model metadata was not being read properly - [Windows] Fixed: Make sure the LM Studio.exe executable is also signed. Should help with anti-virus false positives **Build 4** - [Advanced GPU controls] Allow disabling all GPUs with any engine - [Advanced GPU controls] Fix bug where disabling a GPU would cause incorrect offloading when > 2 gpus - [Advanced GPU controls][CUDA] Improved stability of"Limit Model Offload to Dedicated GPU memory" mode - Added GPU controls logging to "Developer Logs" - Fixed a bug where sometimes editing model config inside the model loader popover does not take effect - Fixed a bug related to renaming state focus on chat cells **Build 5** - [Advanced GPU controls] Enlarge GPU controls pop-out window
さらに詳しく
- 最新のLM StudioアプリをmacOS、Windows、またはLinux用にダウンロードしてください。
- 職場でLM Studioを組織で利用したい場合は、こちらからお問い合わせください:LM Studio @ Work
- 議論やコミュニティのために、私たちのDiscordサーバーに参加してください。
- LM Studioが初めてですか?ドキュメントをご覧ください:ドキュメント:LM Studioを始める。