LM Studio 0.3.4、Apple MLX搭載でリリース
•
2024-10-08
**LM Studio 0.3.4** は、AppleシリコンMacでオンデバイスLLMを非常に効率的に実行するためのMLXエンジンを搭載しています。
Appleシリコン向けLM Studioはこちらからダウンロードできます。LM StudioにおけるMLXの詳細については、以下をお読みください。
M3 Max上のLlama 3.2 1Bは、毎秒約250トークンで動作します。
👾 **システムの設計と構築に興味がありますか?** 私たちは採用活動を行っています。募集中のポジションはこちらをご覧ください。
LM Studio 0.3.4におけるMLXのサポート内容:
- Hugging Faceから、サポートされているMLX LLMを検索&ダウンロード(GGUFモデルと同様に)
- チャットUI、またはローカルホストで実行されているOpenAIライクなローカルサーバーを使用するコードを介して、MLXモデルを使用
- 特定のJSON形式でのLLM応答を強制(Outlinesのおかげで)
- LLaVAなどのビジョンモデルを使用し、チャットまたはAPIを介して使用(mlx-vlmのおかげで)
- 複数のLLMを同時にロードして実行。
llama.cppモデルとMLXモデルを混在させて使用することも可能!
このブログ記事の残りの部分は、LM StudioにおけるMLXの技術的な詳細を深く掘り下げています。
Awni Hannun(MLX)、Rémi Louf(.txt/Outlines)には、このブログ記事の草稿とmlx-engineコードのレビューにご協力いただき、感謝申し上げます。
MLXとは?
...そして、なぜ私が気にする必要があるのでしょうか?
MLXは、Appleの新しいオープンソースAI/MLソフトウェアスタックであり、Appleシリコン向けに最適化されています。AppleのMチップのパワフルなアクセラレーションハードウェアを活用します。
Appleのエンジニアによって開発され、成長を続ける開発者コミュニティによってサポートされているMLXは、MacでオンデバイスAIを実行するための非常に競争力のある選択肢となるでしょう。
MLXコアライブラリはC++で記述されており、コミュニティでサポートされているPythonとSwiftのフロントエンドを備えています。
LM StudioでのMLXのサポートを発表できることを嬉しく思います。このブログ記事では、MLX全般と、LM StudioのMLXエンジンに関する技術的な詳細について説明します。
LM Studioのmlx-engineはオープンソースです
LM StudioのMLXエンジンは、以下のパッケージを組み合わせて構築されたPythonモジュールです。
- mlx-lm - AppleのMLX(Pythonフロントエンド)。Awni Hannun氏とAppleのチームによる。
- Outlines - LLMからの構造化生成。Rémi Louf氏と.txtのチームによる。
- mlx-vlm - AppleのMLX向けビジョンLLM。Prince Canuma氏による。
mlx-engineはMITライセンスのオープンソースです。リポジトリ:https://github.com/lmstudio-ai/mlx-engine。
LM StudioでPythonを使用してMLX?!
MLXをLM Studioに統合するための私たちの取り組みは、Swiftから始まりました。このアプローチは問題なく機能しましたが、最終的には以下の設計目標により、Pythonがより良い選択肢となりました。
**設計目標1:** コミュニティと協力してMLXエンジンを改良したい
- Pythonに精通している開発者や研究者ははるかに多い
**設計目標2:** 最新のモデルや技術がリリースされ次第、サポートできるようにしたい
- PythonのMLXは、新しいモデルのサポートが早く提供される傾向がある
LM Studioにmlx-lmのサポートを追加するには、Pythonコンポーネントを移植可能でクロスプラットフォームな方法でデプロイおよび実行できる必要がありました。理想的には、これらのコンポーネントを、LM Studioアプリケーションのメイン部分で既に使用されている既存のC/C++コンポーネントと完全に統合できるようにしたいと考えていました(最終的には、conda環境など、いくつかの候補となるソリューションを除外することになりました)。
LM Studioの初期Pythonランタイムサポートは、python-build-standaloneプロジェクトとPython仮想環境の上に構築されており、共通のランタイムとフレームワーク層を共有する、個別にダウンロード可能なPythonアプリケーション環境の統合セットの作成をサポートする、近日公開予定のユーティリティを使用しています(結局のところ、合理的に避けられるのであれば、PyTorchやCUDAの複数のコピーをダウンロードしてインストールしたい人はいません)。
この「スタック型仮想環境」ユーティリティは、CPythonインタプリタの「サイトカスタマイズ」機能と、仮想環境の内容に対する公開前およびインストール後の調整を組み合わせて使用することで、これらの仮想環境をマシン間で確実に転送し、含まれるアプリケーション起動モジュールをCPythonの-mコマンドラインスイッチで起動できるようにします。
10月下旬には、この件に関するより詳細な技術的発表が行われる予定です。
ミニ詳解:mlx-engineの機能の一部
MLX を使用したテキスト生成モデルの実行
Python MLXエコシステムの重要な要素は、mlx_lmです。このプロジェクトは、CLIツールまたは数行のPythonコードを使用して、大規模言語モデルを簡単に実行する方法を提供します。例:
generate_step の内部を見て、何が起こっているのかをより深く理解しましょう。
ここで重要な操作が行われていることがわかります。
- モデルは、その
__call__メソッドを使用して評価されます。これは、各要素がモデルの語彙内の項目に対応するロジットの配列を返します。ロジットは、語彙内の項目に対する確率分布を定義します。 - ユーザーが提供したサンプリングパラメータを使用して、ロジットの配列からトークンが選択(つまり、*サンプリング*)されます。
- サンプリングされたトークンは、呼び出し側に返されます。
ユーザーが喜ぶ機能を、この生成ループにどのように追加できるかを見てみましょう。
アウトラインを使用した構造化生成の有効化
ジェネレーターに機能を追加しましょう。ユーザーは、ジェネレーターが有効なJSONを出力するように要求できます。このために、.txt の アウトライン を使用できます。
アウトラインは、LLMからの構造化生成(例:JSON出力の作成)を可能にします。このパッケージには、活用するmlx_lmランタイムのサポートが付属しています。アウトラインは、ユーザーが提供したJSONスキーマを正規表現に変換することで機能します。このタイトルスキーマを見てください。
アウトラインはそのスキーマをこの正規表現文字列に変換します
これは、より人間が読める(ただし、精度は低い)正規表現文字列のバージョンです:\{"title": ".{1,}"\}
この正規表現文字列を使用すると、アウトラインの生成ループは次のようになります。
- モデルを評価します。つまり、プロンプトを処理し、各トークンのロジットを出力します。
- 各トークンについて、それをサンプリングすると正規表現に違反するかどうかを評価します。違反する場合は、その確率をゼロに設定します。ロジットを*マスク*すると言います。
- マスクされたロジットを使用してトークンをサンプリングします。
mlx_lmのgenerate_stepでは、ロジットプロセッサを定義できるため、出力が正規表現と一致するようにロジットをマスクするプロセッサを定義しましょう。
そして、このオブジェクトのインスタンス化を使用してmlx生成ステップを呼び出すことができます
これで完了です! JSONスキーマが提供されるたびにJSONを生成できるようになりました。
MLX を使用したビジョンモデルの実行
MLX Pythonエコシステムのもう1つの要素は、ビジョンLLMを実行するためのパッケージであるmlx_vlmです。簡潔にするために編集された、mlx_vlmのgenerate_stepメソッドを以下に示します。
mlx_vlm実装とmlx_lm実装を比較対照してみましょう。
mlx_vlm評価では、model.__call__メソッドを使用します。最初の評価ではピクセルデータを処理し、後続の評価では基盤となる言語モデルを使用します。mlx_vlmのsample関数で使用できるサンプリングメソッドは、mlx_lmよりも少なくなっています。mlx_vlmにはlogits_processorがありません。
mlx_vlmからビジョンモデルを使用しながら、mlx_lmからのロジット処理とサンプリングを使用すると便利です。それを実装してみましょう!
最初の呼び出しでピクセルデータを評価し、後続の呼び出しで言語モデルを使用するクラスを作成します。
これで、mlx_lm.generate_stepに渡すことができます。
これで、画像でLLMにプロンプトを表示し、タイトルを作成してもらうことができます!
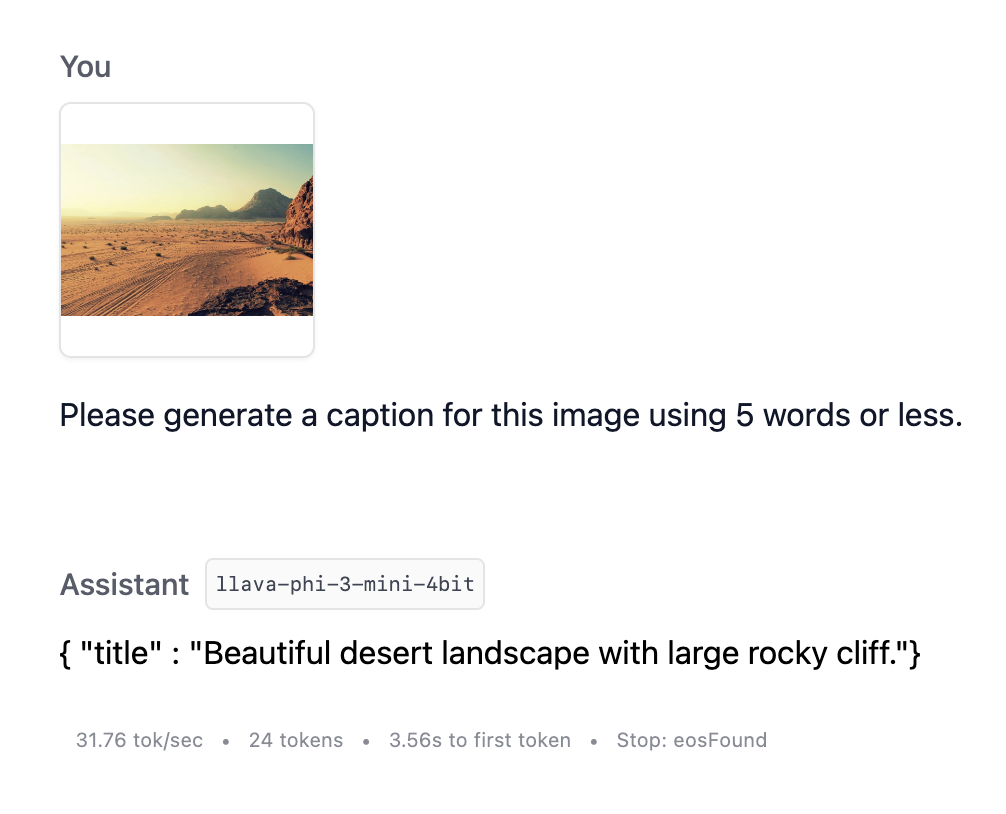
VLMと構造化出力を使用した画像のキャプション
プロンプト間のKVキャッシング
プロンプト間のKV(キーバリュー)キャッシングは、LLMエンジンが以前のインタラクションからの計算を再利用できるようにする最適化手法です。これにより、モデルの応答時間、つまり「最初のトークンまでの時間」を大幅に改善できます。
KVキャッシングは、プロンプトの大部分(チャット履歴)がモデルへの生成リクエスト間で同じであることが多いチャットシナリオで特に役立ちます。
例
**タイムステップ1(T1)**-ユーザーはプロンプト「この長い記事を要約してください:<ここに長い記事...>」を送信します
**タイムステップ2(T2)**-LLMエンジンは入力に対して推論を実行し、モデルの重みと入力トークン埋め込みの間に大きな行列乗算を実行して、出力トークンを生成します:「この記事では、の影響について説明しています...」
**タイムステップ3(T3)**-ユーザーはプロンプト「記事に人物は erwähntされていますか?」を送信します。チャット履歴全体がLLMに送信され、会話を続けるための適切なコンテキストが提供されます。
**タイムステップ4(T4)**-LLMエンジンは入力(**T1**、**T2**、および**T3**からのすべてのトークン)に対して推論を実行し、モデルの重みと入力トークン埋め込みの間に大きな行列乗算を実行して、出力トークンを生成します:「はい、この記事では、次のような主要人物について言及しています...」
KVキャッシング
KVキャッシングは、**T3**に到達するまでに、LLMに「記事に記載されている人物」について質問することで、**T3**で計算する必要があるものと同じ行列計算を**T1**および**T2**で既に実行しているという事実を利用しています。
したがって、**T1**と**T2**の計算結果を**KV CACHE**に保存し、**T3**でエンジンに**KV CACHE**へのアクセスを許可すると、エンジンはプロンプトの新しい部分「記事に人物は記載されていますか?」の計算のみを実行する必要があります。
これにより、**T4**の応答時間が大幅に短縮されます。テストでは、約3000トークンの記事とMeta-Llama-3.1-8B-Instruct-4bitを使用した場合、**T4**の応答時間はKVキャッシングなしの場合は約10秒でしたが、KVキャッシングを使用するとわずか0.11秒に短縮されました。
現在のMLX KVキャッシング実装
実装時点では、mlx-lmは、generate_step関数にcache_historyパラメータを公開していました。
適切なcache_history(上記の**KV CACHE**に似ています)を渡すことで、MLXエンジンにKVキャッシングの初期バージョンを実装できました。
私たちは、`mlx-lm` の PR ファイルから KV キャッシュを読み込む機能の追加 を適用することでこれを実現しました。この PR では、キャッシュラッパー内でモデルを使用してプロンプトを前処理します。
上記の `cache_wrapper.update_cache` は、cache_prompt.py を参照して、チャンクごとにキャッシュを заполняет。
キャッシュが作成され、`generate_args["cache_history"]` に保存されたので、`generate_args` と `generate_step_input` を `mlx_lm.utils.generate_step` に渡すだけで済みます。
これにより、`generate_step` 関数は `cache_history` に格納されている以前の計算結果を利用できるようになり、プロンプト全体を raw 処理する場合と比較して、応答時間を大幅に短縮できます。
この `cache_history` オブジェクトは、プロンプト処理呼び出し間で保存し、それを基に構築することで、非常に長い会話中でもチャットシナリオの応答性を維持できます。ただし、その際には、`cache_history` に処理されたトークンが、プロンプトの先頭トークンに対応していることを確認することが重要です。詳細については、`update_cache` 関数 内のキャッシュリセット動作をご覧ください。
LM Studio 0.3.4 のその他の変更点
新機能
- ミッションコントロール: モデルを検索するには `Cmd+Shift+M`、LM ランタイムを管理するには `Cmd+Shift+R` を使用します。
- UI から構造化出力 (JSON スキーマ) を設定します。
バグ修正
- 長時間使用後のブラックスクリーンの修正 (参考: lmstudio-bug-tracker#98)
- ローカルサーバーで 1234 以外のポートが機能しない問題の修正 (参考: lms#80)
- Obsidian から埋め込み API が機能しない問題の修正 (参考: tracker#142)
- ドキュメント処理中に RAG が失敗することがある問題の修正
さらに
- 最新の **LM Studio** アプリを macOS、Windows、または Linux 用にダウンロードしてください。
- LM Studio を初めてご利用ですか?ドキュメントをご覧ください: ドキュメント: LM Studio のはじめに。
- ディスカッションやコミュニティについては、Discord サーバーにご参加ください。
- 職場の組織で LM Studio を使用したい場合は、ご連絡ください: LM Studio @ Work