LM Studio 0.3.9
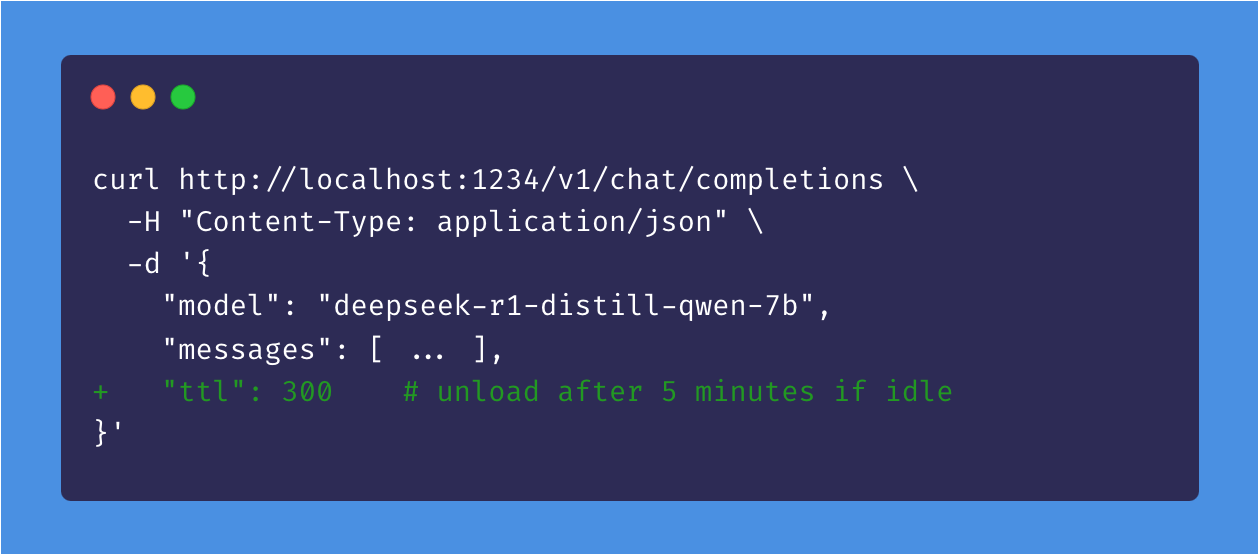
未使用のAPIモデルを一定時間後に自動アンロードするオプション
LM Studio 0.3.9 には、新しい**アイドルTTL**機能、Hugging Faceリポジトリ内のネストされたフォルダーのサポート、およびチャット補完応答でreasoning_contentを別のフィールドで受け取る実験的APIが含まれています。
0.3.9 の以前のビルドには、DeepSeek R1チャット補完応答のストリーミングに関するバグがありました。この問題を修正するには、最新のビルド(5)に更新してください。
アプリ内アップデート、またはhttps://lmstudio.dokyumento.jp/downloadからアップグレードしてください。
アイドルTTLと自動アンロード
ユースケース: LM Studioによって提供されるLLMと対話するために、Zed、Cline、またはContinue.devのようなアプリを使用していると想像してください。これらのアプリは、初めてモデルを使用する際にJITを活用してオンデマンドでモデルをロードします。
問題: モデルをアクティブに使用していない場合、メモリにロードされたままにしたくないことがあります。
解決策: APIリクエストによってロードされたモデルにTTLを設定します。アイドルタイマーは、モデルがリクエストを受信するたびにリセットされるため、使用中にモデルが消えることはありません。モデルは、何の作業もしていない場合にアイドル状態と見なされます。アイドルTTLが期限切れになると、モデルはメモリから自動的にアンロードされます。
TTLはリクエストペイロードで秒単位で設定するか、コマンドラインで使用する場合はlms load --ttl <seconds>を使用できます。
詳細については、ドキュメント記事を参照してください: TTLと自動アンロード。
チャット補完応答におけるreasoning_contentの分離
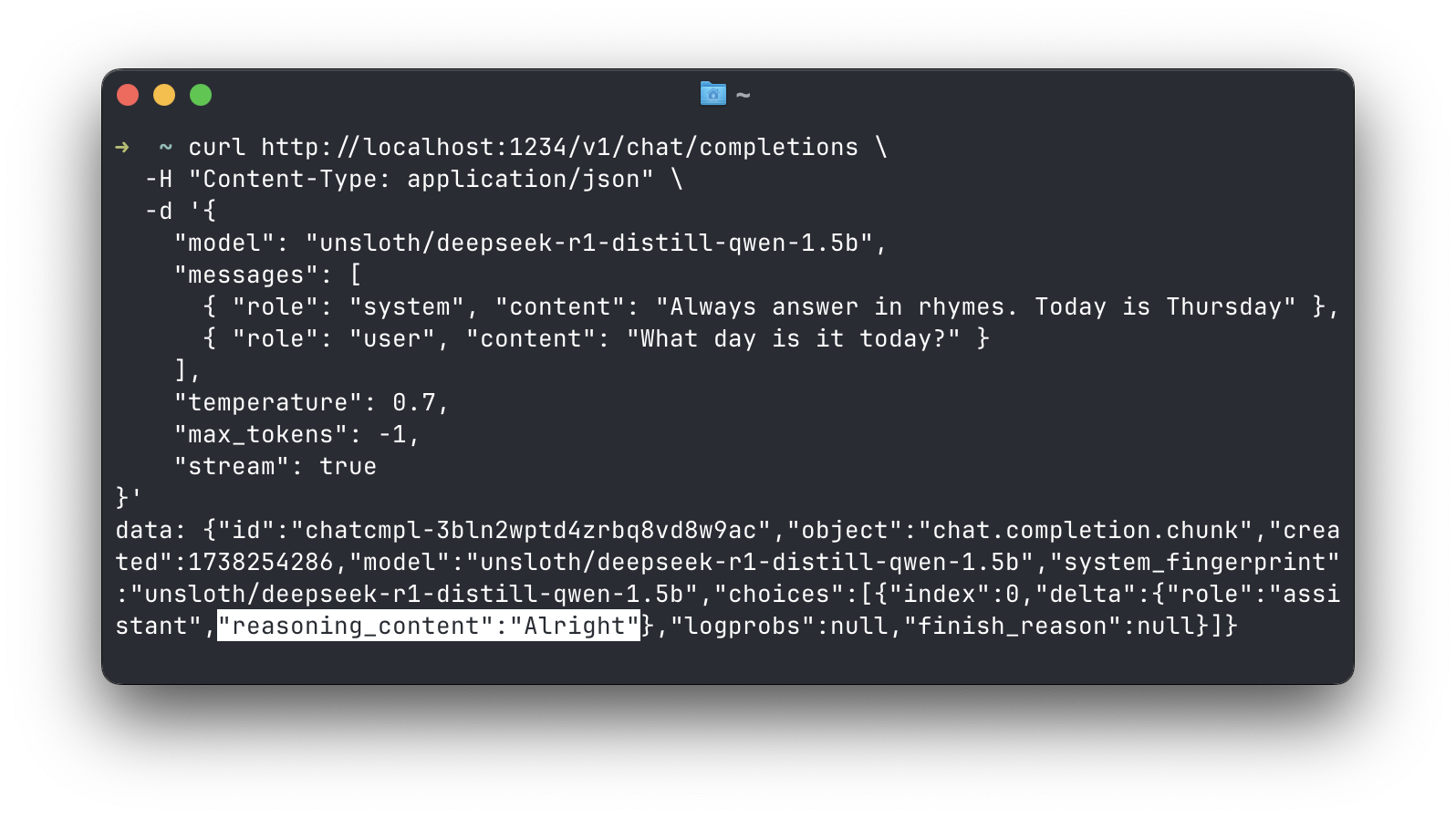
DeepSeek R1の場合、推論内容を別のフィールドで取得
DeepSeek R1モデルは、<think> </think>タグ内でコンテンツを生成します。このコンテンツはモデルの「推論」プロセスです。チャット補完応答では、DeepSeekのAPIのパターンに従って、このコンテンツをreasoning_contentという別のフィールドで受け取ることができるようになりました。
これはストリーミングおよび非ストリーミングの両方の補完で機能します。アプリ設定 > 開発者でこれをオンにできます。この機能は現在実験的です。
注: DeepSeekのドキュメントによると、次のリクエストで推論内容をモデルに返すべきではありません。
LMランタイムの自動更新
LM Studioは、llama.cppエンジンの複数のバリアント(CPUのみ、CUDA、Vulkan、ROCm、Metal)と、Apple MLXエンジンをサポートしています。これらのエンジンは、特に新しいモデルがリリースされる際に頻繁に更新されます。
複数のコンポーネントを手動で更新する手間を減らすため、ランタイムの自動更新を導入しました。これはデフォルトで有効になっていますが、アプリ設定でオフにできます。
ランタイムが更新されると、リリースノートを示す通知が表示されます。ランタイムタブでも自分で管理できます: Windows/LinuxではCtrl + Shift + R、macOSではCmd + Shift + R。

LMランタイムは最新版に自動更新されます。設定でこれをオフにできます
Hugging Faceリポジトリ内のネストされたフォルダーのサポート
長らく要望されていた機能です: Hugging Faceリポジトリ内のネストされたフォルダーからモデルをダウンロードできるようになりました。お気に入りのモデルパブリッシャーがモデルをサブフォルダーで整理している場合、LM Studioで直接ダウンロードできます。
これにより、https://huggingface.co/unsloth/DeepSeek-R1-GGUFのようなモデルを簡単にダウンロードできます。lms get <hugging face url>でも機能します。
# Warning: this is a very large model lms get https://huggingface.co/unsloth/DeepSeek-R1-GGUF
0.3.9 - 完全変更ログ
ビルド6
- 画像を含むチャットでテキスト専用モデルを使用した場合の「Cannot read properties of undefined」エラーを修正
- Windowsで、特定の環境でLMランタイムが予期しない動作をするパス解決の問題を修正
- CUDAモデルのロードクラッシュ、「llm_engine_cuda.node. The file cannot be accessed by the system」
- ROCmでのモデル生成の文字化けを修正
- アプリの古いバージョンで作成されたチャットでRAGメッセージが表示されないバグを修正
- 入力メソッドエディタ(IME)のバグを修正: Enterキーを押しても、変換が完了しない限りメッセージが送信されないようになりました
ビルド5
- DeepSeek R1チャット補完応答のストリーミング時に
reasoning_content設定が尊重されないAPIバグを修正
ビルド4
- 新しい実験的API: チャット補完応答(ストリーミングおよび非ストリーミングの両方)で
reasoning_contentを別のフィールドで送信<think></think>タグ内でコンテンツを生成するモデル(DeepSeek R1など)で機能します- アプリ設定 > 開発者でオンにしてください
ビルド3
- 新機能: 新しく追加された思考UIブロックを自動展開するチャット表示オプションを追加
- 新機能: アプリがシステムリソース不足のエラー通知を出した場合に、ガードレール設定へのクイックアクセスを表示
- デフォルト以外のモデルディレクトリが削除された場合、新しいモデルがインデックスされないバグを修正
- Vulkanバックエンドを使用するマルチGPU設定で、ハードウェア検出がGPUを誤ってフィルタリングしてしまうバグを修正
- モデルロードUIで、フラッシュアテンションなしのF32キャッシュタイプがllama.cpp Metalランタイムの有効な設定として認識されないバグを修正
ビルド2
- 新機能: Hugging Faceリポジトリ内のネストされたフォルダーからのモデルダウンロードのサポートを追加
- Hugging Face URLでの直接検索のサポートを改善
- 新機能: 選択したランタイム拡張パックを自動更新(設定でオフにできます)
- 新機能: LM StudioのHugging Faceプロキシを使用するオプションを追加。これは、Hugging Faceに直接アクセスできないユーザーに役立ちます
- 新機能: MLXモデルのKVキャッシュ量子化(mlx-engine/0.3.0が必要)
- マイモデルタブの更新: モデル名がより整理され、モデルタイプごとにサイドバーカテゴリが追加されました
- アプリ設定 > 一般で完全なファイル名表示に切り替え可能
- 生のモデルメタデータを確認するには(以前は(i)ボタン)、モデル名を右クリックして「生メタデータを表示」を選択してください
- サンプリング設定でTop Kをクリアするとエラーが発生するバグを修正
ビルド1
- 新機能: **TTL** - 未使用のAPIモデルを一定時間後に自動アンロードするオプション(リクエストペイロード内の
ttlフィールド)- コマンドラインでの使用:
lms load --ttl <seconds> - APIリファレンス: https://lmstudio.dokyumento.jp/docs/api/ttl-and-auto-evict
- コマンドラインでの使用:
- 新機能: **自動アンロード** - 新しいAPIモデルをロードする前に、以前にロードされたAPIモデルを自動的にアンロードするオプション(アプリ設定で制御)
- モデルの思考ブロック内の数式が、ブロックの下に空白を生成してしまうバグを修正
- トースト通知内のテキストがスクロールできないケースを修正
- 構造化出力JSONのチェックを外して再度チェックすると、スキーマ値が消えるバグを修正
- 生成中の自動スクロールが、時々上にスクロールすることを許可しないバグを修正
- [開発者向け] ロギングオプションを開発者ログパネルヘッダー(•••メニュー)に移動
- チャット表示のフォントサイズオプションが思考ブロック内のテキストを拡大縮小しないバグを修正
さらに多くの情報
- 最新の**LM Studio**アプリをmacOS、Windows、またはLinux用にダウンロードしてください。
- 職場でLM Studioを組織で利用したい場合は、お問い合わせください: LM Studio @ Work
- 議論やコミュニティについては、Discordサーバーにご参加ください。
- LM Studioは初めてですか?ドキュメントをご覧ください: ドキュメント: LM Studio入門。