LM Studioにおける統一マルチモーダル MLX エンジンアーキテクチャの紹介

LM StudioのMLXエンジン(MIT)は、Apple Silicon Mチップ上でLLMを効率的に実行するために、2つの強力なPythonパッケージを活用しています。テキスト生成にはmlx-lm(@awni、@angeloskath、Appleによる)を、画像対応言語モデルにはmlx-vlm(@Blaizzyによる)を使用しています。
mlx-engineコミット f98317e(アプリ内エンジン v0.17.0以降)から、各パッケージの基盤となるコンポーネントを織り交ぜた新しい統一アーキテクチャに移行しました。これにより、mlx-lmのテキストモデル実装が常に使用され、mlx-vlmのビジョンモデル実装は、テキストモデルが理解できる画像埋め込みを生成するための「アドオン」としてモジュール式に使用されるようになりました。
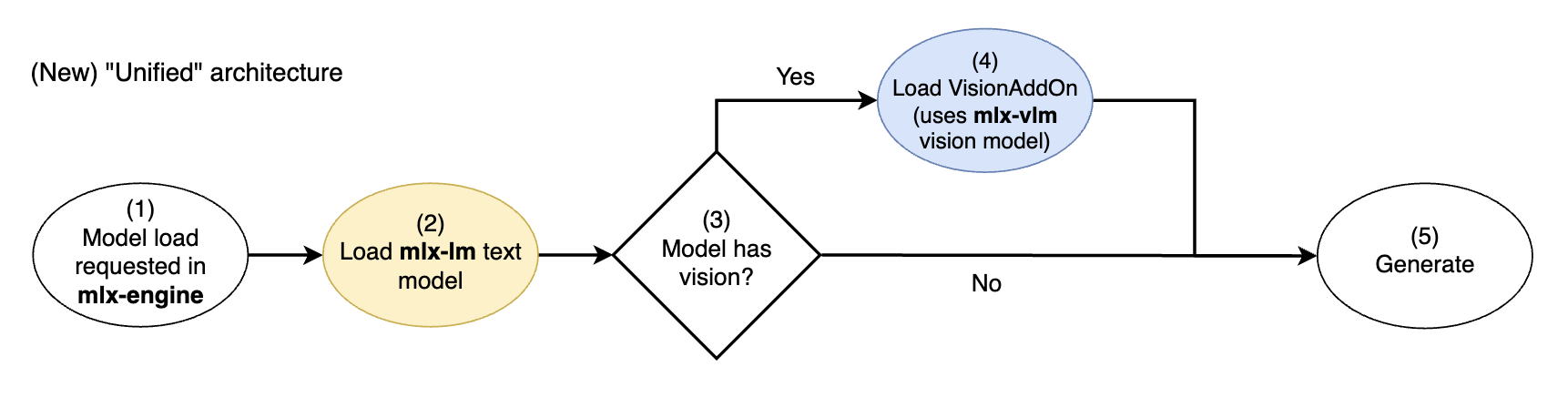
新しいmlx-engineの統一ビジョンモデルアーキテクチャ。mlx-lmテキストモデルはmlx-vlmビジョンアドオンで拡張されます。
これにより、マルチモーダルMLX VLM(例:GoogleのGemma 3)の使用時のパフォーマンスとユーザーエクスペリエンスが大幅に向上しました。例えば、VLMとのテキストのみのチャットで、以前はテキストのみのLLM専用だったプロンプトキャッシュ機能が利用できるようになり、フォローアップ応答が劇的に高速化しました。これにより、MLX VLMは、テキストタスクにおいてテキストのみのLLMとシームレスに互換性があり、さらにビジョン機能もボーナスとして提供されます。
👓 問題、解決策、そしてLM StudioのMLXエンジンでこの統一アーキテクチャをどのように実現したかについての技術的な詳細はこちらをご覧ください。
👷 LM StudioのMLXエンジンへのオープンソース貢献は非常に歓迎されます!より多くのモデルに統一アーキテクチャを拡張したい場合は、このGitHubイシューが素晴らしい出発点となります。
マルチモーダルモデルとは?
マルチモーダルLLMとは、複数の*モダリティ*の入力を受け取ることができるLLMのことです。これは、テキスト入力だけでなく、画像や音声の入力も受け入れることができることを意味します。
新しいMLXエンジンはまだ音声には対応していませんが、このアプローチは音声入力にも対応できるように計画しています。
一般的に、画像対応LLMは以下のフローで画像入力を取り込みます。
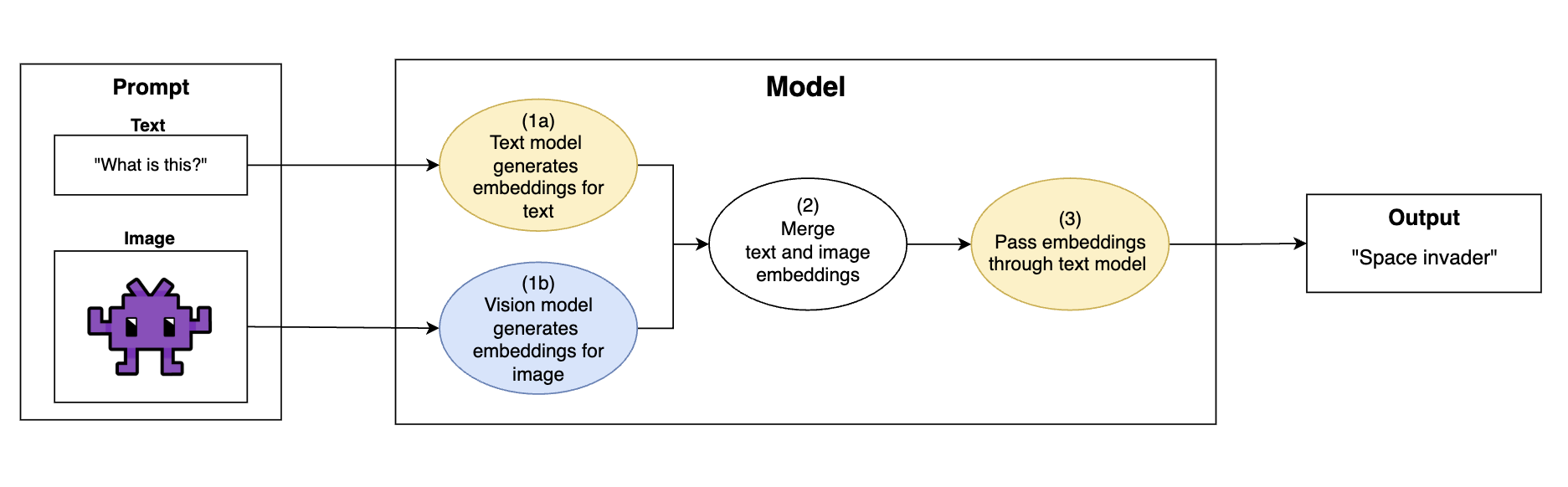
マルチモーダルビジョンLLMの一般的な動作フロー:画像をテキストモデルが理解できる埋め込みに変換し、テキストモデルで出力を生成します。
- テキストと画像を含むプロンプトが入力されます。
- (1a) モデルの「テキスト」部分がテキストをモデルの埋め込み空間にエンコードします。
「これは何ですか?」→[0.83, 0.40, 0.67, ...]
- (1b) モデルの「ビジョン」部分が画像をテキストモデルの埋め込み空間にエンコードします。これにより、画像がテキストモデルが理解できる形式に変換されます。
image.png→[0.28, 0.11, 0.96, ...]
- (2) テキストと画像の埋め込みがマージされます。
[0.83, 0.40, 0.67, ...]+[0.28, 0.11, 0.96, ...]→[0.83, 0.40, 0.67, ..., 0.28, 0.11, 0.96, ...]
- (3) マージされた埋め込みがテキストモデルに渡され、モデルはテキストと画像の両方の情報に基づいてテキストを生成します。
プロンプトに画像が含まれていない場合、「マージされた埋め込み」は単純にテキスト埋め込みとなります。
MLXエコシステムにおけるモデル実装
MLX Pythonの環境では、Apple Silicon上のLLMとの対話のためのモデル実装とインフラストラクチャを提供する2つの主要なライブラリがあります。
歴史的に、mlx-lmにはマルチモーダル機能を持たないテキスト専用モデルの実装が含まれており、一方mlx-vlmはMLX VLM実装の事実上のホームとなっています。
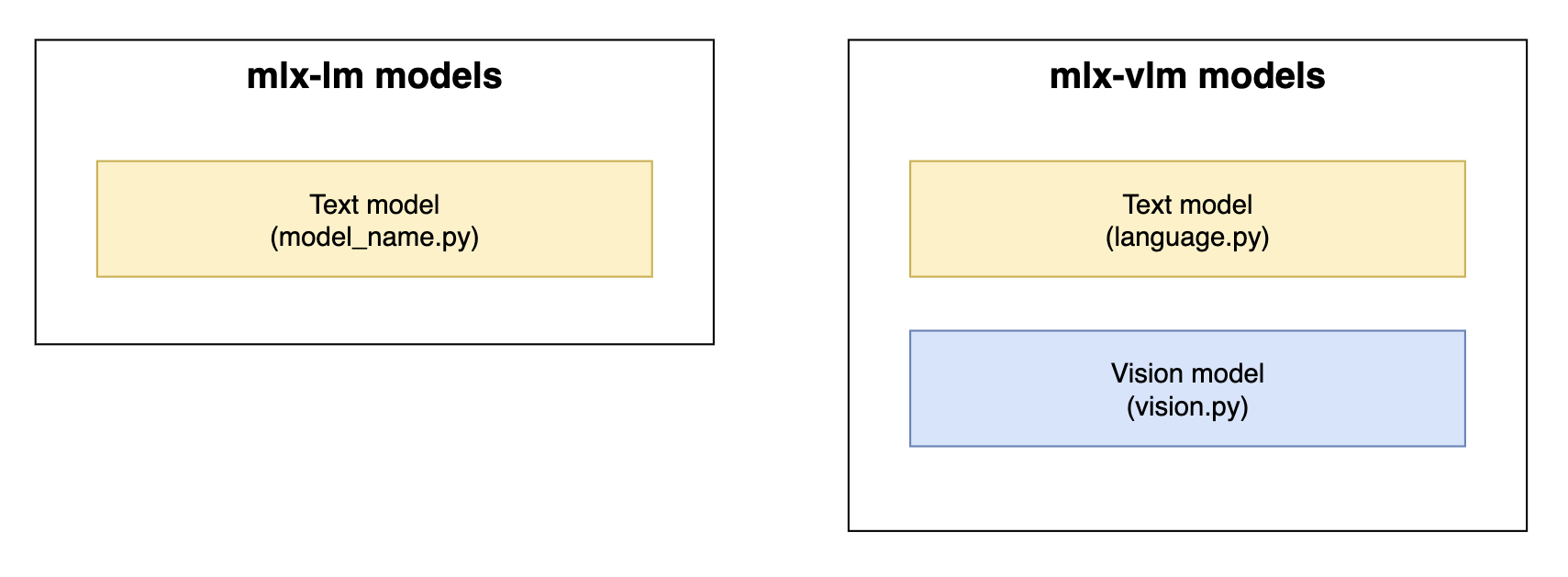
mlx-lmおよびmlx-vlmにおけるモデル実装コンポーネント。黄色 = テキストモデルコンポーネント。青色 = ビジョンモデルコンポーネント
LM Studioのmlx-engineは、当初、テキスト専用モデルと画像対応モデルの両方をサポートするために、シンプルな「フォーク」アーキテクチャで開発されました。
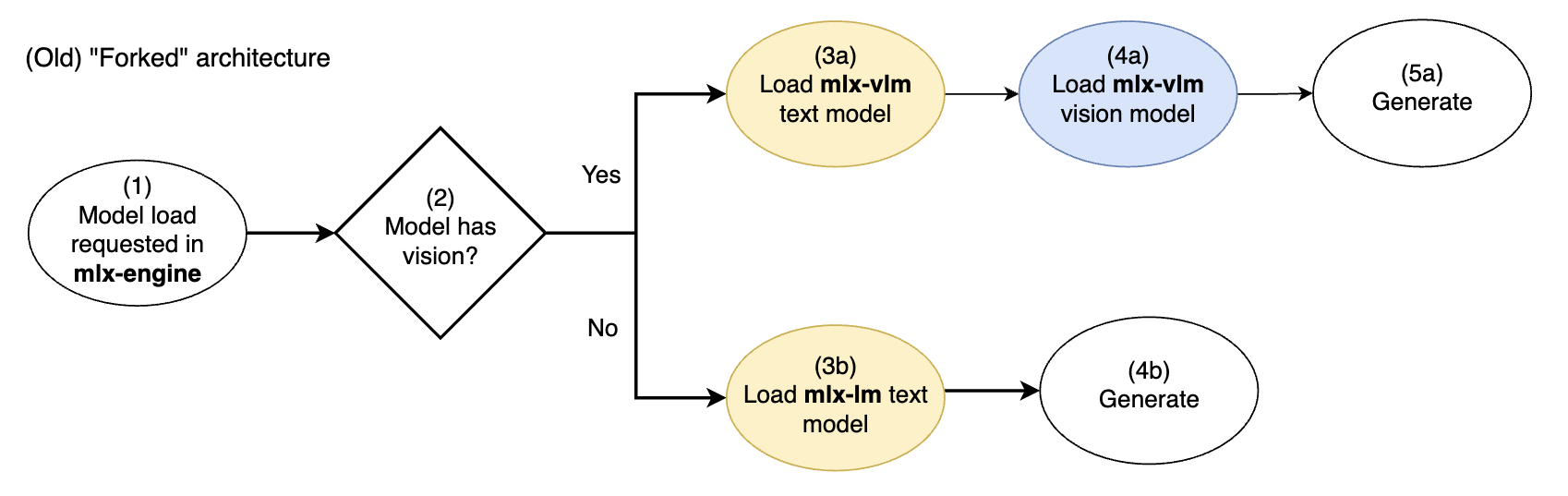
旧mlx-engineのフォークビジョンモデルアーキテクチャ。黄色 = テキストモデルコンポーネント。青色 = ビジョンモデルコンポーネント
モデルが画像対応の場合、mlx-vlmモデル実装(テキスト+ビジョン)が*独占的に*使用されました。モデルがテキスト専用の場合、mlx-lmモデル実装(テキスト)が*独占的に*使用されました。
各パスでは、(mlx-lmまたはmlx-vlmからの)異なるテキストモデル実装が使用されました。
問題:フォークアーキテクチャ
mlx-engineの単純なフォークアーキテクチャは、以下の問題に悩まされていました。
mlx-lmとmlx-vlmの機能が完全に同等でない場合や、微妙な動作の違いがある場合、どちらを使用すべきでしょうか?- マルチモーダルモデルとの対話とテキスト専用モデルとの対話の体験における乖離をどのように制限できるでしょうか?
- 一方の実装が他方よりもパフォーマンスが良い、または他方にはないバグを含んでいると仮定します。
mlx-lmとmlx-vlmのどちらを使用するかをどのように一貫して選択できるでしょうか?リクエストに応じてロードを切り替えるべきでしょうか(複雑)?
- もし両者の間で切り替えを行ったり、マルチモーダルモデルのテキスト専用バリアント(例:このGemma 3テキスト専用モデル)の使用をサポートしたりする場合、バグとメンテナンスの表面積は2倍になります。これは、*同じ*基盤モデルを推論するために2つの別々の実装が条件付きで使用されるためです。したがって、LM Studioでバグのない体験を提供するために、2つの別々のモデルがバグフリーであることを保証する必要があります。
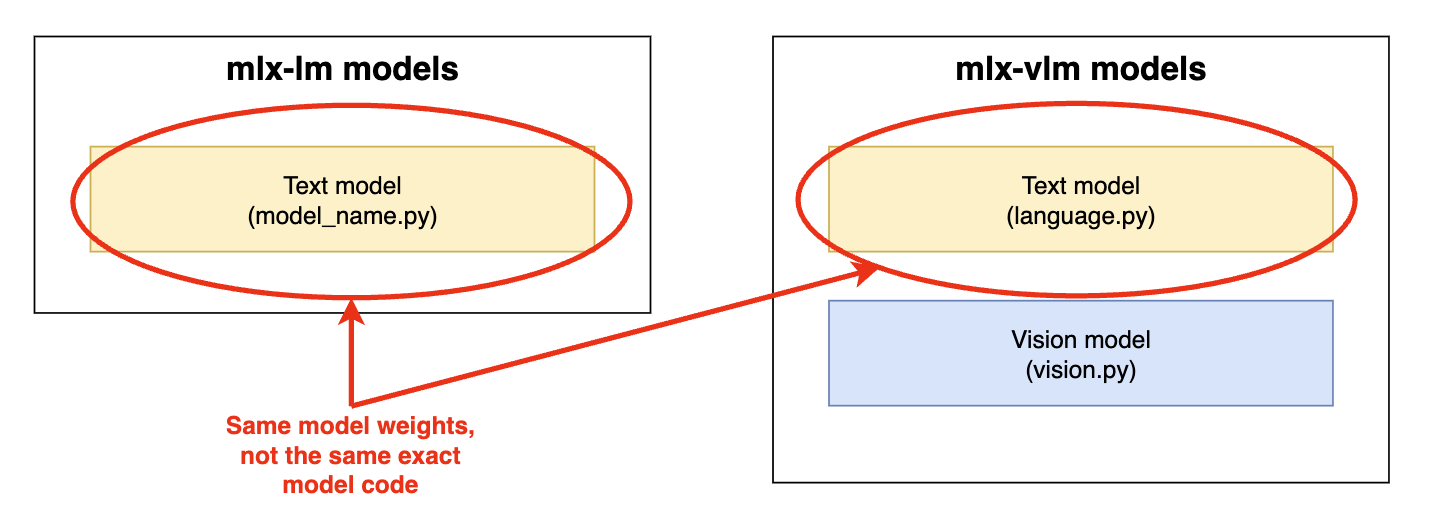
同じテキストモデルの2つの別々のバージョンが存在します。
私たちの解決策:両方の長所を活かす
すべてのMLX LLMおよびVLM向けの「統一」(フォークなし)推論エンジンを作成するために、mlx-lmとmlx-vlmのコアコンポーネントを組み合わせることを目指しました。
@awniおよび@Blaizzyとの貴重な議論を経て、以下の貢献を通じてこれを実現しました。
mlx-lm
mlx-vlm
新しいmlx-engineの統一ビジョンモデルアーキテクチャ。mlx-lmテキストモデルはmlx-vlmビジョンアドオンで拡張されます。
この統一アーキテクチャでは、マルチモーダルLLMのコアテキストモデルは常にmlx-lm(2)からロードされ、わずかに異なるテキストモデルがmlx-vlmからロードされることはなくなりました。
次に、mlx-lmテキストモデルが理解できる画像埋め込みを生成するために、mlx-vlmの機能を使用するVisionAddOnを条件付きでロードします(mlx-engineのGemma3VisionAddOn実装を参照)。
このセットアップにより、マルチモーダルモデルを効率的で単一パスのファッションで推論できるようになりました。これにより、よりクリーンで保守性の高いLM Studio MLXエンジンを、パフォーマンスを向上させてリリースできます。
Gemma 3 12B QAT、M3 MacBook Pro上のMLX 4ビット。統一アーキテクチャにより、フォローアップTTFTが約25倍高速化。
詳細:mlx-engineのVisionAddOns
LM Studioの新しいmlx-engine統一アーキテクチャの要点は、すべてのマルチモーダルモデルに対してmlx-lmからのテキストモデル実装を使用できることであり、同時にmlx-vlmからのビジョンモデルコンポーネントを活用して、テキストモデルが理解できる画像埋め込みを生成できることです。
これは、マルチモーダルモデルの画像埋め込みを生成するために使用できるモジュール式コンポーネントであるVisionAddOns(ソース)を導入することで達成されます。これらのVisionAddOnsは、例えばBaseVisionAddOn抽象クラスによって定義された共通インターフェースを実装しています。
class BaseVisionAddOn: """ Base class that defines the interface for a VisionAddOn. """ @abstractmethod def __init__(self): """ Where load of vision model components is intended to occur. """ @abstractmethod def compute_embeddings( self, text_model: nn.Module, prompt_tokens: mx.array, images_b64: List[str], ) → mx.array: """ Returns input embeddings for the language model after text/image merging of the prompt """
VisionAddOnsは、mlx-lmのstream_generate()関数の新しいinput_embeddings引数に入力できる画像埋め込みを生成します(mlx-lmに行われたコミットを参照)。
現在、Gemma 3(Gemma3VisionAddOn)とPixtral(PixtralVisionAddOn)の2つのモデルのみが統一アーキテクチャに移行されました。しかし、このアーキテクチャは、より多くのVisionAddOnsをmlx-engineのvision_add_onsディレクトリに簡単に追加し、ModelKitのこちらで配線できるように設計されています。
VISION_ADD_ON_MAP = { "gemma3": Gemma3VisionAddOn, "pixtral": PixtralVisionAddOn, }
私たちのオープンソースリポジトリhttps://github.com/lmstudio-ai/mlx-engineでこのパターンを拡張するための貢献を歓迎します!例えば、mlx-engineイシューExtend VisionAddOn Pattern to Qwen2.5VL #167を参照してください。
フィードバックと貢献
- オープンソースの
mlx-engineリポジトリについては、https://github.com/lmstudio-ai/mlx-engineでご覧いただくか、貢献してください。 - 最新のLM Studioは、https://lmstudio.dokyumento.jp/downloadからダウンロードしてください。
- LM Studioを初めてお使いですか?ドキュメントをご覧ください:LM Studio入門。
- ディスカッションやコミュニティについては、Discordサーバーにご参加ください:https://discord.gg/aPQfnNkxGC
- 組織でLM Studioをビジネス利用したい場合は、お問い合わせください:LM Studio @ Work