LM Studio 0.3.4 は Apple MLX を搭載
LM Studio 0.3.4 は、Apple Silicon Mac 上でオンデバイス LLM を非常に効率的に実行するための MLX エンジン を搭載しています。
Apple Silicon 用の LM Studio は こちら からダウンロードできます。MLX in LM Studio についてさらに詳しく知るには、このままお読みください。
Llama 3.2 1B on M3 Max が約 250 トークン/秒で実行
👾 システムのデザインや構築に興味がありますか? 私たちは人材を募集しています。空きポジションについては こちら をご覧ください。
LM Studio 0.3.4 の MLX サポートには以下が含まれます:
- Hugging Face からサポートされている MLX LLM を検索・ダウンロードできます(GGUF モデルでこれまで行ってきたのと同じように)。
- Chat UI を通じて、またはローカルホストで実行される OpenAI ライクなローカルサーバー を使用してコードから MLX モデルを使用できます。
- LLM の応答を特定の JSON フォーマットで強制できます(Outlines による)。
- LLaVA などの Vision モデルを使用でき、チャットまたは API 経由で使用できます(mlx-vlm による)。
- 複数の LLM を同時にロードして実行できます。
llama.cppと MLX モデルを混在させることさえ可能です!
このブログ記事の残りは、LM Studio における MLX の技術的な詳細について掘り下げていきます。
このブログ記事のドラフト、および mlx-engine コードのレビューをしていただいた Awni Hannun (MLX)、Rémi Louf (.txt/Outlines) に特別の感謝を申し上げます。
MLX とは?
そして、なぜ気にする必要があるのでしょうか?
MLX は Apple による新しいオープンソース AI/ML ソフトウェアスタックで、Apple Silicon に特化して最適化されています。Apple の M チップに搭載されている強力なアクセラレーションハードウェアを活用します。
Apple のエンジニアによって開発され、成長中の開発者コミュニティによってサポートされている MLX は、Mac 上でのオンデバイス AI 実行において非常に競争力のある選択肢となるでしょう。
MLX コアライブラリ は C++ で書かれており、コミュニティサポートの Python および Swift フロントエンドが付属しています。
LM Studio における MLX サポートの発表に興奮しています。このブログ記事では、MLX 一般に関する技術的な詳細と、LM Studio の MLX エンジンに特化した詳細をいくつか取り上げます。
LM Studio の mlx-engine はオープンソースです
LM Studio の MLX Engine は、以下のパッケージを組み合わせて構築された Python モジュールです。
- mlx-lm - Apple の MLX (Python フロントエンド)。Awni Hannun と Apple のチームによるものです。
- Outlines - LLM からの構造化生成。Rémi Louf と .txt のチームによるものです。
- mlx-vlm - Apple の MLX 用 Vision LLM。Prince Canuma によるものです。
mlx-engine は MIT ライセンスの下でオープンソースです。リポジトリ: https://github.com/lmstudio-ai/mlx-engine。
LM Studio で MLX を使用... Python で?!
LM Studio への MLX の統合の旅は Swift から始まりました。このアプローチは完全に機能しましたが、最終的には以下の設計目標により Python がより良い選択となりました。
設計目標 1: コミュニティと共に MLX エンジンをイテレーションしたい
- より多くの開発者、研究者が Python に精通しています。
設計目標 2: 最新のモデルやテクニックがリリースされ次第、サポートできるようにしたい
- Python の MLX は、新しいモデルのサポートをより早く受け取る傾向があります。
LM Studio に mlx-lm サポートを追加するには、Python コンポーネントをポータブルでクロスプラットフォームな方法でデプロイおよび実行できる必要がありました。理想的には、メインの LM Studio アプリケーションで既に使われている既存の C/C++ コンポーネントとそれらのコンポーネントを完全に統合できるようにしたいと考えていました(これは、conda 環境 のような一部の候補ソリューションを除外することになりました)。
LM Studio の初期 Python ランタイムサポートは、python-build-standalone プロジェクトと Python 仮想環境の上に構築されており、近日公開予定のユーティリティを使用して、共通のランタイムおよびフレームワークレイヤーを共有する独立してダウンロード可能な Python アプリケーション環境の統合セットを作成します(結局、PyTorch や CUDA のコピーを複数ダウンロードしてインストールしたい人はいません)。
この「スタック仮想環境」ユーティリティは、CPython インタープリタの「サイトカスタマイズ」機能と、仮想環境の内容に対する一部の公開前およびインストール後の調整を使用して、これらの仮想環境をマシン間で確実に転送できるようにし、CPython の -m コマンドラインスイッチで含まれるアプリケーション起動モジュールを呼び出せるようにします。
10月後半に、その分野に関するより詳細な技術発表にご期待ください。
ミニ詳細解説: mlx-engine の一部の機能
MLX を使用したテキスト生成モデルの実行
Python MLX エコシステムの重要な部分である mlx_lm。このプロジェクトは、CLI ツールや数行の Python で大規模言語モデルを簡単に実行する方法を提供します。例:
from mlx_lm.utils import load, generate_step import mlx.core as mx def mlx_stream(prompt: str): model, tokenizer = load("/path/to/mlx/model") prompt_tokens = mx.array(tokenizer.encode(prompt)) while True: yield generate_step( model=model, prompt=prompt_tokens ) for token in mlx_stream(prompt="Hello world!"): print(token, end="", flush=True)
generate_step の内部を見て、何が起こっているかをよりよく理解しましょう。
def generate_step(*args, **kwargs): # --snip-- def sample(logits): logprobs = logits - mx.logsumexp(logits) if temp == 0: token = mx.argmax(logits, axis=-1) else: if top_p > 0 and top_p < 1.0: token = top_p_sampling(logits, top_p, temp) elif min_p != 0.0: token = min_p_sampling(logits, min_p, min_tokens_to_keep, temp) else: token = categorical_sampling(logits, temp) return token, logprobs y = prompt tokens = None def _step(y): logits = model(y[None], cache=cache) logits = logits[:, -1, :] nonlocal tokens tokens = mx.concat([tokens, y]) if tokens is not None else y for processor in logits_processor: logits = processor(tokens, logits) y, logprobs = sample(logits) return y, logprobs.squeeze(0) y, logprobs = _step(y) while True: next_y, next_logprobs = _step(y) yield y.item(), logprobs y, logprobs = next_y, next_logprobs
ここで重要な操作を確認できます。
- モデルは
__call__メソッドを使用して評価されます。これにより、モデルの語彙の各項目に対応するロゴス(logits)の配列が返されます。ロゴスは、語彙の項目に対する確率分布を定義します。 - ユーザー提供のサンプリングパラメータを使用して、ロゴスの配列からトークンが選択(つまり、*サンプリング*)されます。
- そのサンプリングされたトークンが呼び出し元に返されます。
ユーザーが喜ぶような機能をこの生成ループに追加する方法を見てみましょう。
Outlines による構造化生成の有効化
ジェネレーターに機能を追加しましょう:ユーザーは、ジェネレーターに有効な JSON を出力するように要求できます。これには、Outlines を .txt から使用できます。
Outlines は LLM からの構造化生成(例:JSON 出力の作成)を可能にします。このパッケージには mlx_lm ランタイムのサポートが含まれており、これを活用します。Outlines は、ユーザー提供の JSON スキーマを正規表現に変換することで機能します。このタイトルスキーマを見てみましょう。
{ "type": "object", "properties": { "title": { "type": "string", "minLength": 1 } }, "required": [ "title" ] }
Outlines はそのスキーマをこの正規表現文字列に変換します。
\{[ ]?"title"[ ]?:[ ]?"([^"\\\x00-\x1F\x7F-\x9F]|\\["\\]){1,}"[ ]?\}
これは、より人間が読める(ただし、より不正確な)正規表現文字列のバージョンです: \{"title": ".{1,}"\}
この正規表現文字列を使用して、Outlines の生成ループは以下のようになります。
- モデルを評価します。つまり、プロンプトを処理し、各トークンのロゴスを出力します。
- 各トークンについて、それをサンプリングすると正規表現に違反するかどうかを評価します。違反する場合、その確率をゼロに設定します。ロゴスを*マスク*すると言います。
- マスクされたロゴスを使用してトークンをサンプリングします。
mlx_lm の generate_step ではロゴスプロセッサーを定義できるため、出力を正規表現に一致させるようにロゴスをマスクするプロセッサーを定義しましょう。
from outlines.processors.structured import JSONLogitsProcessor class OutlinesJSONLogitsProcessor: def __init__(self, json_schema, tokenizer): self.logits_processor = JSONLogitsProcessor(json_schema, tokenizer) def __call__(self, tokens: mx.array, logits: mx.array): logits_1d = logits.flatten() # convert to 1-dimensional array logits_1d = self.logits_processor(tokens, logits_1d) logits = logits_1d[None] # convert back to original shape return logits
そして、このオブジェクトのインスタンス化で mlx 生成ステップを呼び出すことができます。
def mlx_stream(prompt: str): model, tokenizer = load("/path/to/mlx/model") prompt_tokens = mx.array(tokenizer.encode(prompt)) json_schema='''{"type":"object","properties":{"title":{"type":"string","minLength":1}},"required":["title"]}''' # define schema while True: yield generate_step( model=model, prompt=prompt_tokens, logits_processor=[OutlinesJSONLogitsProcessor(json_schema, tokenizer)] # output valid json )
これで完成です!JSON スキーマが提供されていれば、いつでも JSON を生成できるようになりました。
MLX を使用した Vision モデルの実行
MLX Python エコシステムのもう一つの部分である mlx_vlm は、Vision LLM を実行するためのパッケージです。以下は、簡潔にするために編集された mlx_vlm の generate_step メソッドです。
def generate_step(*args, **kwargs): def sample(logits: mx.array) → Tuple[mx.array, float]: if temp == 0: token = mx.argmax(logits, axis=-1) else: if top_p > 0 and top_p < 1.0: token = top_p_sampling(logits, top_p, temp) else: token = mx.random.categorical(logits * (1 / temp)) return token, logprobs # --snip-- def _step(y): logits = model.language_model(y[None], cache=cache, mask=mask) logits = logits[:, -1, :] y, logprobs = sample(logits) return y, logprobs.squeeze(0) y = prompt logits = model(y, pixel_values, cache=cache, mask=mask) logits = logits[:, -1, :] y, logprobs = sample(logits) while True: next_y, next_logprobs = _step(y) yield y.item(), logprobs y, logprobs = next_y, next_logprobs
mlx_vlm の実装と mlx_lm の実装を比較対照しましょう。
mlx_vlmの評価ではmodel.__call__メソッドを使用します。最初の評価でピクセルデータを処理し、その後の評価では基盤となる言語モデルを使用します。mlx_vlmのsample関数は、mlx_lmよりも利用可能なサンプリングメソッドが少なくなっています。mlx_vlmには logits_processor はありません。
mlx_lm のロゴス処理とサンプリングを使用しつつ、mlx_vlm の Vision モデルも使用するのは有益でしょう。それを実装しましょう!
最初の呼び出しでピクセルデータを評価し、それ以降の呼び出しで言語モデルを使用するクラスを記述します。
class VisionModelWrapper: def __init__(self, vision_model, image_processor, pixel_values, mask): self.vision_model = vision_model self.image_processor = image_processor self.pixel_values = pixel_values self.mask = mask self.first_call = False def __call__(self, *args, **kwargs): if self.pixel_values is not None and not self.first_call: self.first_call = True return self.vision_model(self.input_ids, self.pixel_values, self.mask, **kwargs) else: return self.vision_model.language_model(*args, mask=self.mask, **kwargs)
そして、これを mlx_lm.generate_step に渡すことができます。
def mlx_stream(prompt: str): # load and wrap the vision model vision_model_dict, tokenizer = load_vision_model("/path/to/mlx/vision_model", "/path/to/image") vision_model_wrapper = VisionModelWrapper(**vision_model_dict) prompt_tokens = mx.array(tokenizer.encode(prompt)) json_schema='''{"type":"object","properties":{"title":{"type":"string","minLength":1}},"required":["title"]}''' while True: yield generate_step( model=vision_model_wrapper, prompt=prompt_tokens, logits_processor=[OutlinesJSONLogitsProcessor(json_schema, tokenizer)] )
これで、画像で LLM にプロンプトを与え、タイトルを作成させることができます!
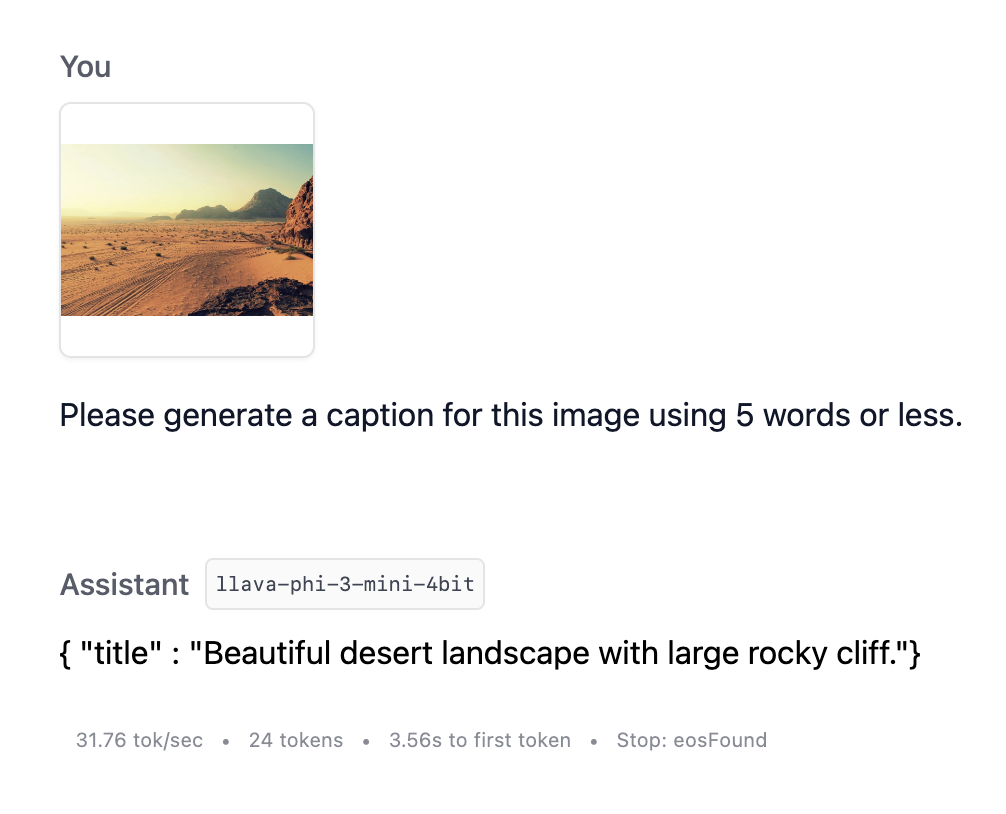
VLM と構造化出力を使用した画像のキャプション作成
プロンプトをまたぐ KV キャッシュ
プロンプトをまたぐ KV (キーバリュー) キャッシュは、LLM エンジンが以前のやり取りからの計算を再利用できるようにする最適化技術です。これにより、モデルの応答時間、「最初のトークンまでの時間」を大幅に改善できます。
KV キャッシュは、チャットシナリオで特に価値があります。チャット履歴の大部分は、モデルへの生成リクエスト間で同じであることが多いためです。
例
タイムステップ 1 (T1) - ユーザーがプロンプトを送信します: "この長い記事を要約してください: <長い記事はこちら...>"
{ "User" : "Summarize this long article: <long article here...>" }
タイムステップ 2 (T2) - LLM エンジンは入力に対して推論を実行し、モデルの重みと入力トークン埋め込みの間で大規模な行列演算を計算して、出力トークンを生成します: "この記事は、~への影響について論じています..."
{ "User" : "Summarize this long article: <long article here...>", "AI" : "This article discusses the impact of..." }
タイムステップ 3 (T3) - ユーザーがプロンプトを送信します: "記事に言及されている人物はいますか?"。会話の文脈を正しく与えるために、チャット履歴全体が LLM に送信されます。
{ "User" : "Summarize this long article: <long article here...>", "AI" : "This article discusses the impact of...", "User" : "Are there any people mentioned in the article?" }
タイムステップ 4 (T4) - LLM エンジンは入力(T1、T2、T3 のすべてのトークン)に対して推論を実行し、モデルの重みと入力トークン埋め込みの間で大規模な行列演算を計算して、出力トークンを生成します: "はい、記事には~を含むいくつかの主要人物が言及されています..."
{ "User" : "Summarize this long article: <long article here...>", "AI" : "This article discusses the impact of...", "User" : "Are there any people mentioned in the article?", "AI" : "Yes, the article mentions several key figures, including..." }
KV キャッシュ
KV キャッシュは、T3 にいる時点で、「記事に言及されている人物はいますか?」と LLM に尋ねる場合、T1 と T2 で実行された行列計算が、T3 で実行される必要がある計算と同じであることを利用します。
{ # START OF PREVIOUSLY COMPUTED "User" : "Summarize this long article: <long article here...>", "AI" : "This article discusses the impact of..." # END OF PREVIOUSLY COMPUTED "User" : "Are there any people mentioned in the article?" }
したがって、T1 と T2 の計算結果を KV CACHE に保存し、T3 でエンジンに KV CACHE へのアクセス権を与えると、エンジンは新しい部分のプロンプト、"記事に言及されている人物はいますか?" に対してのみ計算を実行すればよくなります。
{ KV CACHE, "User" : "Are there any people mentioned in the article?" }
T4 の応答時間を大幅に改善できます。当社のテストでは、約 3000 トークンの記事と Meta-Llama-3.1-8B-Instruct-4bit を使用した場合、KV キャッシュなしの T4 の応答時間は約 10 秒から、KV キャッシュありではわずか 0.11 秒に短縮されました。
現在の MLX KV キャッシュ実装
実装当時、mlx-lm は generate_step 関数に cache_history パラメータ を公開していました。
def generate_step( *args, cache_history: Optional[List[Tuple[mx.array, mx.array]]] = None, **kwargs ) → Generator[Tuple[mx.array, mx.array], None, None]:
適切な cache_history (上記の KV CACHE に相当)を渡すことで、MLX エンジンに KV キャッシュの初期バージョンを実装できました。
mlx-lm の PR Add the ability to load the KV cache from a file を適応させたことで、プロンプトをキャッシュラッパー内でモデルを通して事前に処理しました。
def process_prompt(self, prompt_tokens, cache_wrapper, generate_args) → mx.array: """ This method processes the prompt and adds its tokens to the cache history """ # --snip-- # prefill cache with prompt_tokens, except those that need to have a repetition penalty applied # (repetition penalty not currently possible for cached tokens) if "repetition_context_size" not in generate_args: generate_args["repetition_context_size"] = ( 20 # default value for mlx_lm.utils.generate_step ) repetition_context_size = generate_args["repetition_context_size"] cache_history, generate_step_input = cache_wrapper.update_cache( prompt_tokens, num_tokens_to_exclude=repetition_context_size ) generate_args["cache_history"] = cache_history return generate_step_input
上記の cache_wrapper.update_cache は、cache_prompt.py からチャンクごとにキャッシュを埋めるために参照しています。
# adapted from https://github.com/ml-explore/mlx-examples/blob/324184d670ec11916a5e92314171d497b312eefe/llms/mlx_lm/cache_prompt.py#L121-L137 step_size = 512 processed: int = 0 while processed < len(tokens_to_process): # Here we evaluate the input prompt chunk by chunk to fill the cache chunk: mx.array = tokens_to_process[processed:processed+step_size] self.model(chunk[None], cache=self.cache) mx.eval([c.state for c in self.cache]) self.tokens: mx.array = mx.concatenate([self.tokens, chunk]) if self.tokens is not None else chunk processed += chunk.size
キャッシュが作成され generate_args["cache_history"] に保存されたら、generate_args と generate_step_input を mlx_lm.utils.generate_step に渡すだけで済みます。
# `process_prompt` function from above generate_step_input = process_prompt(prompt_tokens, cache_wrapper, generate_args) max_tokens = generate_args.pop("max_tokens") for (token, _), n in zip( # generate_step_input is now just the uncached repetition penalty tokens # generate_args has "cache_history" member, set in `process_prompt` mlx_lm.utils.generate_step(generate_step_input, model, **generate_args), range(max_tokens), ):
これにより、generate_step 関数は、cache_history に保存された以前の計算を活用して、プロンプト全体をそのまま処理する場合と比較して応答時間を大幅に短縮できます。
この cache_history オブジェクトをプロンプト処理呼び出し間で保存し、それを構築していくことで、長い会話中でもチャットシナリオを応答性高く保つことができます。ただし、cache_history に処理されたトークンが、プロンプトの先頭トークンに対応していることを確認することが重要です。これに関する詳細は、update_cache 関数 のキャッシュリセット動作を参照してください。
LM Studio 0.3.4 での新機能
新機能
- ミッションコントロール: モデル検索は
Cmd+Shift+M、LM ランタイム管理はCmd+Shift+R - UI から構造化出力(JSON スキーマ)を設定
バグ修正
- 長時間の使用後に発生するブラックアウトの修正(参照: lmstudio-bug-tracker#98)
- ローカルサーバーでポート 1234 以外が機能しない問題の修正(参照: lms#80)
- Obsidian から埋め込み API が機能しない問題の修正(参照: tracker#142)
- RAG がドキュメント処理中に失敗することがあった問題の修正
さらに詳しく
- 最新の LM Studio アプリを macOS、Windows、または Linux 用にダウンロードしてください。
- LM Studio を初めてお使いですか?ドキュメントをご覧ください: ドキュメント: LM Studio の始め方。
- ディスカッションやコミュニティについては、Discord サーバーにご参加ください。
- 組織で LM Studio を利用したい場合は、お問い合わせください: LM Studio @ Work