ドキュメント
インテグレーション
Model Context Protocol (MCP)
モデル (model.yaml)
API
インテグレーション
Model Context Protocol (MCP)
モデル (model.yaml)
API
高度な設定
Speculative Decoding
高度な設定
Speculative Decoding
ドラフトモデルで生成を高速化
高度な設定
選択的デコーディングは、応答品質を低下させることなく、大規模言語モデル(LLM)の生成速度を大幅に向上させることのできる技術です。
選択的デコーディングとは
選択的デコーディングは、2つのモデルの協調に依存します
- より大きく、「メイン」のモデル
- より小さく、高速な「ドラフト」モデル
生成中、ドラフトモデルは潜在的なトークン(サブワード)を急速に提案し、メインモデルはそれらをゼロから生成するよりも速く検証できます。品質を維持するために、メインモデルはドラフトモデルが生成したトークンと一致するものだけを受け入れます。最後に受け入れられたドラフトトークンの後、メインモデルは常に1つの追加トークンを生成します。
ドラフトモデルとして使用されるモデルは、メインモデルと同じ「語彙」を持っている必要があります。
選択的デコーディングを有効にする方法
Power Userモード以上で、モデルをロードし、チャットサイドバーの「選択的デコーディング」セクションでドラフトモデルを選択します。
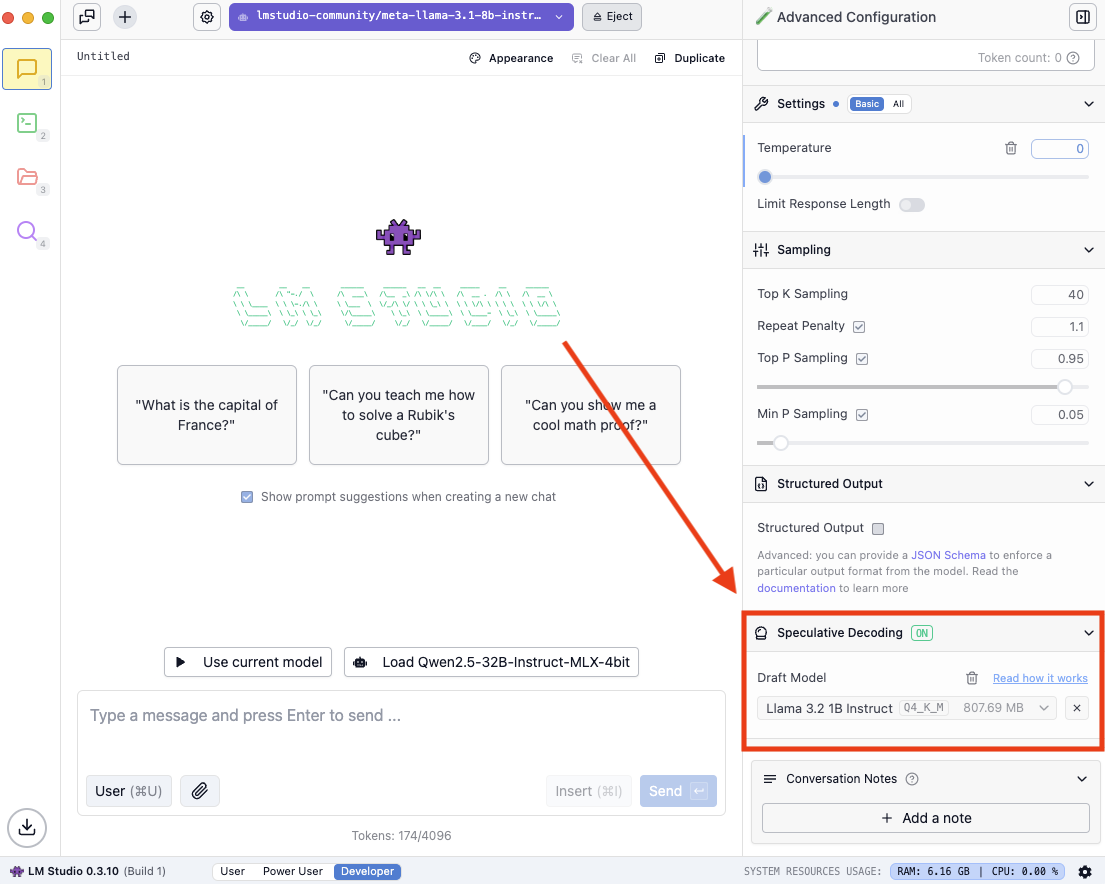
チャットサイドバーの選択的デコーディングセクション
互換性のあるドラフトモデルを見つける
ドロップダウンを開くと、以下のような表示が見られる場合があります
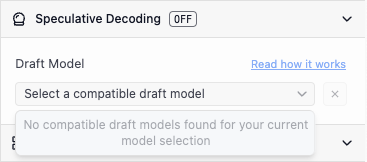
互換性のあるドラフトモデルはありません
ロードしたモデルの、より低パラメータのバリアントが存在する場合は、それをダウンロードしてみてください。お使いのモデルに小さいバージョンが存在しない場合は、互換性のあるペアリングを探してください。
例
| メインモデル | ドラフトモデル |
|---|---|
| Llama 3.1 8B Instruct | Llama 3.2 1B Instruct |
| Qwen 2.5 14B Instruct | Qwen 2.5 0.5B Instruct |
| DeepSeek R1 Distill Qwen 32B | DeepSeek R1 Distill Qwen 1.5B |
メインモデルとドラフトモデルの両方をロードしたら、チャットを開始するだけで選択的デコーディングが有効になります。
パフォーマンスに影響を与える主な要因
選択的デコーディングによる速度向上は、一般的に2つの要因に依存します
- ドラフトモデルがメインモデルと比較して、どれだけ小さく高速か
- ドラフトモデルが「良い」提案をどれくらいの頻度で行えるか
簡単に言えば、メインモデルよりもはるかに小さいドラフトモデルを選択することです。また、プロンプトによっては効果が異なる場合があります。
重要なトレードオフ
選択的デコーディングを有効にするために、ドラフトモデルをメインモデルと並行して実行するには、メインモデルのみを実行するよりも多くの計算とリソースが必要です。
メインモデルの生成速度を向上させる鍵は、小さくて十分な能力を持つドラフトモデルを選択することです。
以下は、メインモデルのサイズ(パラメータ数)に基づいて選択すべきドラフトモデルの最大サイズに関する一般的なガイドラインです。
| メインモデルのサイズ | 速度向上が期待できる最大ドラフトモデルサイズ |
|---|---|
| 3B | - |
| 7B | 1B |
| 14B | 3B |
| 32B | 7B |
一般的に、メインモデルとドラフトモデルのサイズ差が大きいほど、速度向上も大きくなります。
注意: ドラフトモデルが十分に高速でなく、メインモデルへの「良い」提案を行うのに効果的でない場合、生成速度は増加せず、実際には低下する可能性があります。
プロンプト依存性
選択的デコーディングを使用していると、生成速度がすべてのプロンプトで一定ではないことに気づくでしょう。
速度向上がすべてのプロンプトで一定ではない理由は、一部のプロンプトでは、ドラフトモデルがメインモデルに「良い」提案を行う可能性が低いからです。
この概念を説明する極端な例をいくつか示します。
1. 離散的な例: 数学的な質問
プロンプト: 「二次方程式の公式は何ですか?」
この場合、70Bモデルと0.5Bモデルの両方が、標準的な公式 x = (-b ± √(b² - 4ac))/(2a) を提供する可能性が非常に高いです。したがって、ドラフトモデルがこの公式を次のトークンとして提案した場合、ターゲットモデルはおそらくそれを受け入れ、これが選択的デコーディングが効率的に機能する理想的なケースとなります。
2. クリエイティブな例: 物語生成
プロンプト: 「『ドアがギシギシと開いた…』で始まる物語を書いてください。」
この場合、小さいモデルのドラフトトークンは、大きいモデルによって拒否される可能性が高くなります。なぜなら、次の単語は無数の有効な可能性に分岐する可能性があるからです。
「2+2」の「4」という答えは唯一合理的な答えですが、この物語は「モンスターが現れた」、「風が唸る中」、「サラは凍りついた」など、数百の完全に有効な続きで展開する可能性があり、小さいモデルの特定の単語予測が、大きいモデルの選択と一致する可能性ははるかに低くなります。
このページのソースは GitHub で入手できます。
このページについて
選択的デコーディングとは
選択的デコーディングを有効にする方法
互換性のあるドラフトモデルを見つける
パフォーマンスに影響を与える主な要因
重要なトレードオフ
プロンプト依存性
- 1. 離散的な例: 数学的な質問
- 2. クリエイティブな例: 物語生成